
MySQL 学习笔记
1. 初识数据库
1.1 数据库分类
关系型数据库:(RDB)
✅ 特点:
• 结构化数据:数据以表格(table)的形式存储,每张表有固定的列结构。
• 数据关系明确:表与表之间可以通过主键(Primary Key)和外键(Foreign Key)建立关系。
• 支持SQL语言:使用结构化查询语言(SQL)进行数据操作。
• 事务支持强:遵循ACID原则(原子性、一致性、隔离性、持久性),适用于需要高数据一致性的场景。
📚 常见的关系型数据库:
• MySQL
• PostgreSQL
• Oracle
• Microsoft SQL Server
非关系型数据库:(NoSQL-> Not Only SQL)
✅ 特点:
• 灵活的数据结构:不使用表结构,支持多种数据模型,如键值对、文档、列族、图形等。
• 高扩展性:通常设计为分布式系统,易于水平扩展(scale out)。
• 高性能:适用于高并发读写、海量数据处理。
• 最终一致性:通常采用CAP理论中强调可用性和分区容忍性,牺牲部分一致性。
📚 常见的非关系型数据库:
| 类型 | 数据模型 | 代表数据库 |
|---|---|---|
| 键值存储 | Key-Value | Redis, Riak |
| 文档型 | JSON/XML等文档 | MongoDB, CouchDB |
| 列族型 | 类似HBase表 | Cassandra, HBase |
| 图数据库 | 节点+边结构 | Neo4j, ArangoDB |
1.2 MySQL 简介
MySQL是一个关系型数据库管理系统(DBMS),体积小、速度快、成本低。
1.3 MySQL 基本命令
注意,进入sql以后所有的语句都以 ; 结尾
- 命令行连接
1 | mysql -u[用户名] -p[密码] --连接数据库 |
- 基本命令
1 | show databases; -- 查看所有数据库 |
- 有关注释
1 | 单行注释: |
2. 操作数据库
操作数据库 -> 操作数据库中的表 -> 操作数据库中表的数据
mysql关键字不区分大小写
2.1 操作数据库
- 创建数据库
1 | CREATE DATABASE [if not exists] 数据库名; |
- 删除数据库
1 | DROP DATABASE [if EXISTS] 数据库名; |
- 使用数据库
1 | USE 数据库名; |
- 查看所有数据库
1 | SHOW DATABASES; |
2.2 数据库列的数据类型
整型
tinyint1 字节smallint2 字节mediumin3 字节int4 字节bigint8 字节
浮点型
float4 字节double8 字节decimal主要用于表示精确的小数,特别适合像金钱、财务等对精度要求非常高的场景
字符串
char定长大小字符串,长度为 0~255varchar可变长字符串,长度为 0~65535tinytext微型文本,长度为 2^8-1text文本串,长度为 2^16-1
时间日期
dataYYYY-MM-DDtimeHH: mm: ssdatatimeYYYY-MM-DD HH: mm: sstimestamp时间戳,1970.1.1 到现在的毫秒数year年份
2.3 数据库的字段属性
Unsigned:
- 无符号的整数
- 声明了该列不能声明为负数
AUTO_INCREMENT:
- 自增,默认自动在上一条记录的基础上+1
- 通常用来设计唯一的主键,如index,必须是整数类型
- 可以自定义设计主键自增的起始值和步长
NULL:
- 假设设置为 not null,如果不填值,就会报错
- 假设设置为 null,如果不填值,默认就是null
DEFAULT:
- 设置字段的默认值,如果不指定该列的值,则会使用默认的值
2.4 创建数据库表
1 | -- 目标:创建一个school数据库表 |
创建表的格式:
1 | CREATE TABLE [IF NOT EXISTS] 表名 ( |
常用命令:
1 | SHOW CREATE DATABASE 数据库名; -- 查看创建的数据库 |
2.5 数据表的属性
表引擎 ENGINE
在 MySQL 中最常见的引擎有两个:
| 引擎名 | 是否支持事务 | 是否支持外键 | 是否支持表锁 | 是否支持行锁 | 说明 |
|---|---|---|---|---|---|
| InnoDB | ✅ | ✅ | ✅ | ✅ | MySQL 默认引擎,支持事务、行级锁,非常可靠 |
| MyISAM | ❌ | ❌ | ✅ | ❌ | 轻量级、查询快,但不支持事务与外键 |
在物理空间存放的位置
- InnoDB 存储结构:
| 文件类型 | 作用 |
|---|---|
| *.frm | 表结构 |
| *.ibd | 数据 + 索引(InnoDB Data) |
- MyISAM 存储结构:
| 文件类型 | 作用 |
|---|---|
| *.frm | 表结构(字段名、类型等) |
| *.MYD | 数据文件(MyData) |
| *.MYI | 索引文件(MyIndex) |
表的字符集编码 CHARSET 与排序规则 COLLATE
1 | CHARSET=utf8 |
如果在 CREATE TABLE 时没有显式指定编码方式(字符集和排序规则),MySQL 会采用当前数据库的默认字符集和排序规则。
2.6 修改与删除表
- 修改表名
1 | RENAME TABLE 原表名 TO 新表名; -- 推荐 |
- 增加表的字段
1 | ALTER TABLE 表名 ADD COLUMN 字段名 数据类型 [字段属性] [COMMENT '注释']; |
- 修改表的字段
两种方式:MODIFY 和 CHANGE
| 修改方式 | 用途 | 是否可改字段名 |
|---|---|---|
| MODIFY | 修改字段类型、属性、默认值 | ❌ 不改字段名 |
| CHANGE | 修改字段名 + 类型/属性等 | ✅ 可以改名字 |
1 | ALTER TABLE 表名 MODIFY 列名 新数据类型 [字段属性] [COMMENT '注释']; |
🔍 对比总结:
| 特性 | MODIFY | CHANGE |
|---|---|---|
| 改字段名 | ❌ 不可以 | ✅ 可以 |
| 改字段类型 | ✅ 可以 | ✅ 可以 |
| 改字段默认值 | ✅ 可以 | ✅ 可以 |
| 改注释 | ✅ 可以 | ✅ 可以 |
| 字段名写几次 | 1 次 | 2 次(旧名 + 新名) |
| 写法是否简洁 | ✅ 更简洁 | 稍麻烦,但功能更强 |
- 删除表的字段
1 | ALTER TABLE 表名 DROP COLUMN 字段名; -- COLUMN 是可选的,也可以省略 |
- 删除表
1 | DROP TABLE [IF EXISTS] 表名; |
3. MySQL 数据管理
3.1 外键(了解即可)
方式一:在创建表时添加外键(麻烦)
1 | create TABLE `grade`( |
方式二: 创表后添加外键约束
1 | create TABLE `grade`( |
删除有外键关系的表的时候,必须要先删除引用了其他表的表,再删除被引用的表。
以上的操作都是物理外键,数据库级别的外键,不建议使用!(避免数据库过多造成困扰)
最佳实践:
- 数据库就是单纯的表,只用来存储数据,只有行(数据)和列(字段)
- 我们想使用多张表的数据、使用外键时应该用程序去实现
🧩 这种说法背后体现的是——“应用控制数据完整性”的设计哲学
也就是这样一种思路:
数据库只管存数据,不负责“聪明”。
所有约束、关系、逻辑检查,全交给应用程序来控制。
3.2 DML 语言
SQL 语言有不同的类型,这些是 MySQL 支持的核心:
| 类型 | 作用说明 | 关键词示例 |
|---|---|---|
| DDL(数据定义语言) | 用于定义数据库结构(表、字段) | CREATE, ALTER, DROP |
| DML(数据操作语言) | 用于操作数据记录(增删改) | INSERT, UPDATE, DELETE |
| DQL(数据查询语言) | 用于查询数据 | SELECT |
| DCL(数据控制语言) | 控制访问权限、安全 | GRANT, REVOKE |
| TCL(事务控制语言) | 控制事务提交、回滚, | COMMIT, ROLLBACK, SAVEPOINT |
The first D stands for database, and the last L stands for language.
此处重点讲解 DML 语言。
3.3 INSERT
1 | -- The grammar is as follows: |
3.4 UPDATE
1 | -- Grammar: |
涉及到WHERE条件匹配,此处补充一些常见操作符:
| 操作符 | 含义 | 说明 | 示例 | 结果 |
|---|---|---|---|---|
| = | 等于 | 判断是否相等 | WHERE name = ‘张三’ | 名字是张三 |
| != 或 <> | 不等于 | 判断是否不等 | WHERE sex != ‘男’ | 不是男的 |
| > | 大于 | 数值比较 | WHERE age > 18 | 大于18岁 |
| < | 小于 | 数值比较 | WHERE id < 10 | id 小于10 |
| BETWEEN | 范围 | 包含边界 | WHERE age BETWEEN 18 AND 22 | 18~22岁 |
| IN | 属于 | 匹配多个值 | WHERE gradeid IN (1,3,5) | 年级为1, 3或5 |
| LIKE | 模糊匹配 | % 表示任意字符 | WHERE name LIKE ‘李%’ | 姓李的 |
| IS NULL | 为空 | 判断字段是否为空 | WHERE email IS NULL | 邮箱为空 |
| AND | 并且 | 同时满足多个条件 | WHERE sex=’女’ AND age=18 | 18岁的女生 |
| OR | 或者 | 满足其中一个即可 | WHERE age < 18 OR age > 60 | 未成年或老年 |
3.5 DELETE and TRUNCATE
1 | DELETE FROM 表名 WHERE 条件; |
删除整张表的所有数据,还可以使用 TRUNCATE
1 | TRUNCATE TABLE 表名; |
两者区别:
| 比较点 | DELETE | TRUNCATE |
|---|---|---|
| 删除数据 | ✅ 是 | ✅ 是 |
| 是否支持 WHERE | ✅ 支持(可条件删除) | ❌ 不支持(只能全表删除) |
| 是否记录日志 | ✅ 一条一条记录(影响性能) | ✅ 只记录结构变更,性能更好 |
| 是否可回滚(InnoDB) | ✅ 可以回滚 | ❌ 不支持事务,不能回滚 |
| 是否触发触发器 | ✅ 会触发 DELETE 触发器 | ❌ 不触发任何触发器 |
| 是否保留表结构 | ✅ 是(只是删数据) | ✅ 是 |
| 是否释放表空间 | ❌ 一般不释放(InnoDB) | ✅ 通常会释放数据页 |
| 是否影响自增(AUTO_INCREMENT) | ❌ 不会,编号继续递增 | ✅ 会重置为从 1 开始 |
4. DQL 查询数据(最核心)
SELECT 的具体语法,一定得按顺序写需求:
1 | SELECT [DISTINCT] 列名1, 列名2, ... |
4.1 基本查询
1 | -- Grammar: |
4.2 去重查询
1 | SELECT DISTINCT 列名1, 列名2, ... FROM 表名; |
假设有如下一张表:
| id | name | gradeid |
|---|---|---|
| 1 | 张三 | 1 |
| 2 | 李四 | 2 |
| 3 | 王五 | 1 |
| 4 | 赵六 | 2 |
| 5 | 张三 | 1 |
则:
1 | SELECT DISTINCT name FROM student; |
结果:
| name |
|---|
| 张三 |
| 李四 |
| 王五 |
| 赵六 |
1 | SELECT DISTINCT gradeid FROM student; |
结果:
| gradeid |
|---|
| 1 |
| 2 |
1 | SELECT DISTINCT name, gradeid FROM student; |
结果:
| name | gradeid |
|---|---|
| 张三 | 1 |
| 李四 | 2 |
| 王五 | 1 |
| 赵六 | 2 |
4.3 查询的一些例子
假设 student 表如下:
| id | name | age | gradeid | birthdate |
|---|---|---|---|---|
| 1 | 张三 | 18 | 1 | 2004-03-10 |
| 2 | 李四 | 22 | 2 | 2000-06-15 |
| 3 | 王五 | 20 | 1 | 2002-09-20 |
| 4 | 赵六 | 21 | 3 | 2001-12-05 |
| 5 | 钱七 | 17 | 2 | 2005-11-11 |
✅ 1. 数学运算
查询:计算学生的 age * gradeid 结果,并显示为 age_grade_product。
1 | SELECT name, age, gradeid, age * gradeid AS age_grade_product FROM student; |
结果:
| name | age | gradeid | age_grade_product |
|---|---|---|---|
| 张三 | 18 | 1 | 18 |
| 李四 | 22 | 2 | 44 |
| 王五 | 20 | 1 | 20 |
| 赵六 | 21 | 3 | 63 |
| 钱七 | 17 | 2 | 34 |
✅ 2. 字符串连接(CONCAT())
查询:将 name 和 age 列合并,显示为 full_name。
1 | SELECT CONCAT(name,'(',age,')') AS full_name FROM student; |
结果:
| full_name |
|---|
| 张三 (18岁) |
| 李四 (22岁) |
| 王五 (20岁) |
| 赵六 (21岁) |
| 钱七 (17岁) |
✅ 3. 日期和时间的计算(DATE_ADD())
查询:计算每个学生生日后的 5 年。
1 | SELECT name, birthdate, DATE_ADD(birthdate, INTERVAL 5 YEAR) AS birthdate_plus_5_years |
结果:
| name | birthdate | birthdate_plus_5_years |
|---|---|---|
| 张三 | 2004-03-10 | 2009-03-10 |
| 李四 | 2000-06-15 | 2005-06-15 |
| 王五 | 2002-09-20 | 2007-09-20 |
| 赵六 | 2001-12-05 | 2006-12-05 |
| 钱七 | 2005-11-11 | 2010-11-11 |
✅ 4. 常量
查询:返回常量 School 作为 school_name。
1 | SELECT 'School' AS school_name |
结果:
| school_name |
|---|
| School |
✅ 5. 条件表达式(CASE)
查询:判断学生是否成年,如果年龄大于或等于 18 则为“成年”,否则为“未成年”。
1 | SELECT name, age, |
结果:
| name | age | age_group |
|---|---|---|
| 张三 | 18 | 成年 |
| 李四 | 22 | 成年 |
| 王五 | 20 | 成年 |
| 赵六 | 21 | 成年 |
| 钱七 | 17 | 未成年 |
4.4 where 条件子句
基本语法:
1 | SELECT 列名 FROM 表名 WHERE 条件; |
关于where的条件,前文已经提及,此处不再赘述。
4.5 模糊查询
在 MySQL 中,模糊查询用于查找符合特定模式的数据,而不是完全匹配数据。模糊查询通常与 LIKE 或者 REGEXP 操作符结合使用。
✅ LIKE 操作符
LIKE 是 MySQL 中用于模糊匹配字符串的标准操作符。它支持两种通配符:
- %:表示零个或多个字符。
- _:表示单个字符。
1 | -- Grammar: |
例如:
1 | -- 查询名称以“张”开头的学生 |
✅ IN 操作符
1 | SELECT 列名 FROM 表名 WHERE 列名 IN (值1, 值2, 值3, ...); |
4.6 联表查询
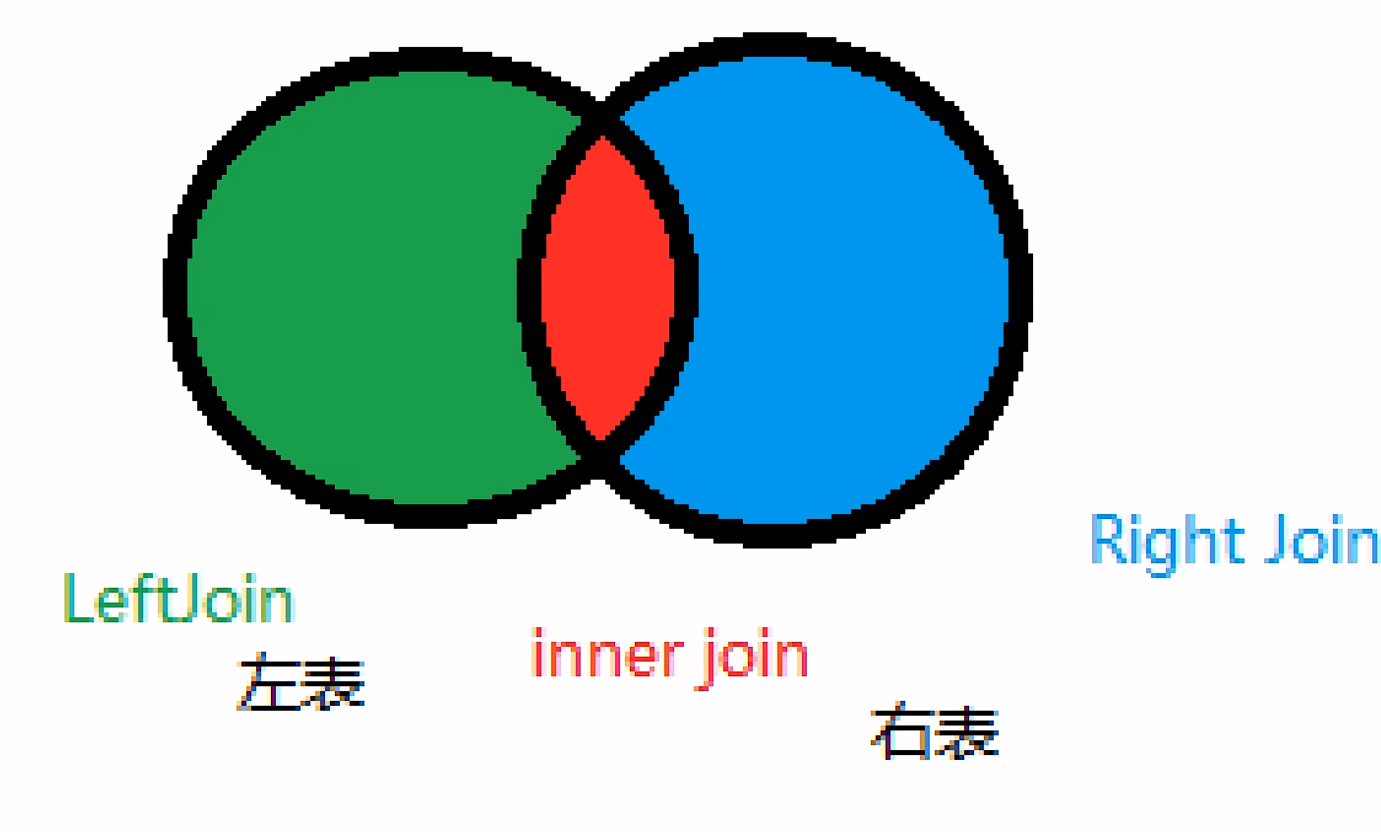
1. 左表与右表
在联表查询中,左表和右表是指在JOIN 操作中,第一个表和第二个表的位置。它们的定义取决于你写查询时的顺序:
左表:在 JOIN 语句中,FROM 后面第一个提到的表就是左表。
右表:在 JOIN 语句中,JOIN 后面提到的表就是右表。
假设我们有以下 student 表:
| student_id | name | gradeid | age | gender |
|---|---|---|---|---|
| 1 | 张三 | 1 | 18 | 男 |
| 2 | 李四 | 2 | 22 | 女 |
| 3 | 王五 | 1 | 20 | 男 |
| 4 | 赵六 | 3 | 21 | 女 |
| 5 | 钱七 | NULL | 17 | 男 |
以及 grade 表:
| gradeid | gradename |
|---|---|
| 1 | 大一 |
| 2 | 大二 |
| 3 | 大三 |
| 4 | 大四 |
2. INNER JOIN(内连接)
INNER JOIN 返回两个表中匹配的记录。
如果某个表中没有匹配的记录,它不会出现在结果集中。
1 | -- grammar: |
结果:
| name | gradename |
|---|---|
| 张三 | 大一 |
| 李四 | 大二 |
| 王五 | 大一 |
| 赵六 | 大三 |
3. LEFT JOIN(左外连接)
定义: LEFT JOIN 返回**左表(FROM 后面的表)的所有记录,以及右表(JOIN 后面的表)**中匹配的记录。如果右表没有匹配的记录,右表的字段会返回 NULL。
1 | -- grammar: |
结果:
| name | gradename |
|---|---|
| 张三 | 大一 |
| 李四 | 大二 |
| 王五 | 大一 |
| 赵六 | NULL |
4. RIGHT JOIN(右外连接)
定义: RIGHT JOIN 返回**右表(JOIN 后面的表)的所有记录,以及左表(FROM 后面的表)**中匹配的记录。如果左表没有匹配的记录,左表的字段会返回 NULL。
1 | -- grammar: |
结果:
| name | gradename |
|---|---|
| 张三 | 大一 |
| 李四 | 大二 |
| 王五 | 大一 |
| NULL | 大三 |
5. FULL JOIN
定义:
FULL JOIN 返回两个表的所有记录。如果某个表没有匹配的记录,结果中会显示 NULL。
MySQL 不直接支持 FULL JOIN,但可以通过 LEFT JOIN 和 RIGHT JOIN 的组合来实现。
1 | SELECT student.name, grade.gradename |
结果:
| name | gradename |
|---|---|
| 张三 | 大一 |
| 李四 | 大二 |
| 王五 | 大一 |
| 赵六 | NULL |
| NULL | 大三 |
6. 三表及以上联表查询
假设有以下四张表:
1. student 表(学生信息)
| student_id | name | gradeid | age | gender |
|---|---|---|---|---|
| 1 | 张三 | 1 | 18 | 男 |
| 2 | 李四 | 2 | 22 | 女 |
| 3 | 王五 | 1 | 20 | 男 |
| 4 | 赵六 | 3 | 21 | 女 |
| 5 | 钱七 | NULL | 17 | 男 |
2. grade 表(年级信息)
| gradeid | gradename |
|---|---|
| 1 | 大一 |
| 2 | 大二 |
| 3 | 大三 |
| 4 | 大四 |
3. course 表(课程信息)
| course_id | coursename | gradeid |
|---|---|---|
| 1 | 数学 | 1 |
| 2 | 英语 | 2 |
| 3 | 物理 | 1 |
| 4 | 化学 | 3 |
| 5 | 历史 | 4 |
4. student_course 表(学生与课程的关系)
| student_id | course_id |
|---|---|
| 1 | 1 |
| 1 | 3 |
| 2 | 2 |
| 3 | 3 |
| 4 | 4 |
| 5 | 5 |
假设要查询学生姓名、年级名称以及他们所选的课程名称。我们需要连接 student、grade 和 course 三张表:
1 | SELECT grade.gradename, student.name, GROUP_CONCAT(course.coursename) AS courses |
结果:
| name | gradename | courses |
|---|---|---|
| 张三 | 大一 | 数学, 物理 |
| 李四 | 大二 | 英语 |
| 王五 | 大一 | 物理 |
| 赵六 | 大三 | 化学 |
| 钱七 | NULL | 历史 |
4.7 自连接
自连接就是连接同一张表,表被分成两个别名来进行比较。
在自连接中,我们需要给同一个表指定不同的别名,以便在查询中区分它们。
假设有一个 employee 表,记录了员工信息和他们的经理(manager_id):
| employee_id | name | manager_id |
|---|---|---|
| 1 | 张三 | NULL |
| 2 | 李四 | 1 |
| 3 | 王五 | 1 |
| 4 | 赵六 | 2 |
| 5 | 钱七 | 3 |
目标:查询每个员工的名字和其经理的名字:
1 | SELECT E1.name AS employee_name, E2.name AS manager_name |
结果:
| employee_name | manager_name |
|---|---|
| 张三 | NULL |
| 李四 | 张三 |
| 王五 | 张三 |
| 赵六 | 李四 |
| 钱七 | 王五 |
通过 LEFT JOIN,我们确保即使员工没有经理(如张三),也能返回该员工的记录,经理名字则为 NULL。
4.8 分页和排序
1. 排序
排序是 SQL 查询中非常常见的操作,用于控制查询结果的顺序。你可以根据一个或多个字段进行排序,并且可以指定升序或降序排列
✅ ORDER BY 的基本语法:
1 | SELECT 列名 |
按多个字段排序的示例:
假设你有如下 student 表:
| student_id | name | age | gradeid |
|---|---|---|---|
| 1 | 张三 | 18 | 1 |
| 2 | 李四 | 22 | 2 |
| 3 | 王五 | 20 | 1 |
| 4 | 赵六 | 21 | 2 |
| 5 | 钱七 | 18 | 1 |
1 | SELECT * FROM student |
排序时的 NULL 值处理:
在 SQL 中,NULL 值的排序方式可能会有所不同,通常:
在 升序排序时,NULL 会被当作最小值排在最前面。
在 降序排序时,NULL 会被当作最大值排在最后面。
2. 分页
分页(Pagination) 是在数据库查询中非常常见的操作,它帮助你将大量数据分批显示,通常用于 Web 应用中的“下一页”和“上一页”按钮,或者 API 返回分段数据。分页不仅可以提高性能,避免一次性返回过多数据,还能提升用户体验。
✅ 分页的基本语法:
1 | SELECT 列名 |
4.9 子查询
子查询(Subquery) 是在 SQL 查询中嵌套的查询,它允许你在主查询中使用另一个查询的结果。子查询可以放在 SELECT、FROM、WHERE、HAVING 等子句中,通常用来提供某些值、结果集或者在查询过程中进行计算。
子查询的优势在于,它允许你避免多次写查询语句,并且可以将复杂的查询逻辑封装在一个查询中。
1. 标量子查询(返回单个值)
例如:查询 年龄大于等于年级“大一”最年轻学生的年龄 的学生信息
1 | SELECT name, age |
2. 列子查询(返回单列值)
例如:假设你想查询所有 gradeid 在学生表中的年级列出的学生,你可以使用 IN 结合子查询
1 | SELECT name, age |
子查询与联表查询比较
✅ 子查询与联表查询的适用场景:
| 操作 | 适用情况 | 优点 | 缺点 |
|---|---|---|---|
| 联表查询(JOIN) | - 多个表之间有明确关系时 - 需要高效的查询性能 - 大数据量的查询 | - 查询效率较高 - 可以利用数据库优化器的优化算法 - 对多表的关联查询非常高效 | - 查询可能更复杂 - 需要处理表间关联关系 |
| 子查询(Subquery) | - 当查询逻辑复杂时 - 需要使用某个值来过滤记录时 - 计算聚合值时 | - 查询结构较为简单 - 可以用来封装复杂查询逻辑 | - 查询效率较低,尤其是多次执行子查询时 - 性能问题,特别是在数据量大的时候 |
在实际查询中,优先考虑使用联表查询(JOIN),只有在复杂查询逻辑需要时,才考虑使用子查询。
5. MySQL 函数
5.1 常用函数
数学函数
1 | -- 计算绝对值 |
字符串函数
1 | -- LENGTH() 函数:返回字符串的字节数。 |
时间和日期函数
1 | -- 获取当前日期 |
系统函数
1 | -- 返回系统的当前用户名 |
5.2 聚合函数
COUNT
1 | -- 计算某列的行数(包括 NULL 值) |
- 其他
1 | -- 计算某列的总和 |
5.3 分组过滤
分组过滤(Group Filtering) 是对查询结果进行分组后的数据进行筛选的过程。它通常与 GROUP BY 和 HAVING 子句一起使用。GROUP BY 用来将查询结果按指定的列进行分组,而 HAVING 用来对分组后的结果进行过滤。
✅ 分组过滤的基本原理
GROUP BY:将数据按指定的字段进行分组,通常与聚合函数(如 COUNT()、SUM()、AVG())一起使用。
HAVING:对分组后的结果进行筛选,类似于 WHERE 子句,但 WHERE 用于筛选行数据,而 HAVING 用于筛选分组后的数据。
✅ 基本语法:
1 | SELECT 列名, 聚合函数(列名) |
✅ HAVING 与 WHERE 的区别:
WHERE 用于在分组之前筛选数据,过滤原始数据行。
HAVING 用于在分组之后筛选数据,过滤已经分组的结果。
示例:
假设我们有一个 sales 表,记录了每个销售员的销售情况:
| sales_id | salesperson | amount |
|---|---|---|
| 1 | 张三 | 500 |
| 2 | 李四 | 600 |
| 3 | 张三 | 300 |
| 4 | 李四 | 200 |
| 5 | 王五 | 600 |
如果我们想查询每个销售员的总销售额:
1 | SELECT salesperson, SUM(amount) AS total_sales |
结果:
| salesperson | total_sales |
|---|---|
| 张三 | 800 |
| 李四 | 800 |
| 王五 | 600 |
假设我们只想查询 总销售额大于 700 的销售员:
1 | SELECT salesperson, SUM(amount) AS total_sales |
结果:
| salesperson | total_sales |
|---|---|
| 张三 | 800 |
| 李四 | 800 |
5.4 SELECT 小结
1 | SELECT [ALL | DISTINCT] |
6. 事务
6.1 什么是事务
要么都成功,要么都失败
在 MySQL 中,事务(Transaction) 是一组操作的集合,这些操作作为一个单独的单元执行。事务要么完全成功(提交),要么完全失败(回滚)。事务保证了数据库的一致性和完整性,确保多个操作要么全部执行,要么全部不执行。
✅ 事务的四个特性(ACID 特性)
- 原子性(Atomicity):(要么都成功,要么都失败)
事务是最小的执行单位,要么全部成功,要么全部失败。如果事务中的一个操作失败,所有的操作都会回滚,数据库保持一致性。
- 一致性(Consistency):(事务前后的数据完整性要保证一致)
事务在执行前后,数据库的状态必须是合法的。即事务执行前后,数据库应从一个一致的状态转变到另一个一致的状态。
- 隔离性(Isolation):(事务之间互不干扰)
事务的执行不应被其他事务干扰。即事务之间应该是独立的,执行事务时,其他事务不能看到中间状态,直到事务提交。
- 持久性(Durability):(事务一旦提交则不可逆)
一旦事务提交,其对数据库的改变是永久的,即使系统崩溃也不会丢失。
6.2 事务的基本语法
1 | SET autocommit=0; -- 关闭自动提交 |
例如,假设有一个账户表 account:
| id | name | balance |
|---|---|---|
| 1 | 张三 | 1000 |
| 2 | 李四 | 1000 |
现在,张三要向李四转账 200 元:
1 | SET autocommit=0; |
注意:哪些引擎支持事务?
存储引擎 是否支持事务 InnoDB ✅ 支持 MyISAM ❌ 不支持
6.3 并发事务问题
隔离性会导致的一些问题:
在数据库事务处理中,脏读(Dirty Read)、不可重复读(Non-repeatable Read) 和 幻读(Phantom Read) 是三种常见的并发问题。它们都与事务之间的隔离性有关,具体体现在一个事务如何与其他并发事务交互。
- 脏读
脏读发生在一个事务读取了另一个事务尚未提交的数据。当第二个事务回滚时,第一个事务读取的数据就变得无效。
- 不可重复读
不可重复读发生在一个事务两次读取同一数据时,第二次读取的数据与第一次读取的数据不同,原因是另一个事务在中间修改了数据
- 幻读
幻读发生在一个事务读取了一组数据,另一个事务插入、更新或删除了这些数据,导致第一个事务再次读取时结果发生变化。通常是因为插入了满足查询条件的新行。
6.4 事务的隔离级别
在数据库中,多用户并发操作时,每个用户的操作都可能影响其他用户的操作。事务隔离级别就是用来规定多个事务在并发执行时彼此“看得见什么数据”的规则。
MySQL 提供的 4 种事务隔离级别(从低到高)
隔离级别越高,安全性越高,但性能会慢慢降低。
| 隔离级别 | 能否读取未提交数据(脏读) | 会不会不可重复读 | 会不会出现幻读 |
|---|---|---|---|
| READ UNCOMMITTED(读未提交) | ✅ 可能读到脏数据 | ✅ 可能 | ✅ 可能 |
| READ COMMITTED(读已提交) | ❌ 不读脏数据 | ✅ 可能 | ✅ 可能 |
| REPEATABLE READ(可重复读) | ❌ | ❌ 保证一致读取 | ✅ 可能(MySQL 可防) |
| SERIALIZABLE(可串行化) | ❌ | ❌ | ❌ 不会 |
怎么查看 / 设置事务隔离级别?
1 | SELECT @@transaction_isolation; |
设置当前会话隔离级别:
1 | SET SESSION TRANSACTION ISOLATION LEVEL 级别; |
7. 索引
1. 索引的定义
根据 MySQL 官方的定义,索引(Index) 是一种用于帮助 MySQL 高效获取数据的数据结构。
索引 就像是书的目录,用来加快你查找数据的速度。
如果没有索引,MySQL 查询时会从头到尾一行一行地找(全表扫描),非常慢。
有了索引,MySQL 可以快速定位目标行,大大提升查询效率,特别是在大表中效果非常明显。
2. 索引的分类
| 索引类型 | 说明 | 示例 |
|---|---|---|
| 普通索引(INDEX) | 最基本的索引,没有任何限制 | CREATE INDEX idx_name ON user(name); |
| 唯一索引(UNIQUE) | 索引列的值必须唯一(可包含 NULL) | CREATE UNIQUE INDEX uniq_email ON user(email); |
| 主键索引(PRIMARY KEY) | 不允许 NULL 且唯一,一个表只能有一个主键 | PRIMARY KEY (id) |
| 全文索引(FULLTEXT) | 用于文本搜索,支持 MATCH AGAINST 语法 | CREATE FULLTEXT INDEX idx_ft ON article(content); |
根据索引的存储方式,也可以将索引分为以下两种:
| 特性 | 聚集索引(Clustered Index) | 辅助索引(Secondary Index) |
|---|---|---|
| 存储结构 | B+Tree,叶子节点存放 整行数据 | B+Tree,叶子节点存放 主键值 |
| 数量限制 | 每个表 只能有一个 | 可以有多个 |
| 是否影响数据的物理排序 | ✅ 是,数据按聚集索引排序 | ❌ 否,不影响数据的物理顺序 |
| 是否需要回表查询 | ❌ 不需要,数据已经在索引中 | ✅ 需要,必须通过主键再查一次 |
| 访问速度 | 查询主键或覆盖索引时更快 | 查询非主键字段时可能慢一步 |
| 默认依据 | 默认是 主键;如果没有主键,会选择第一个唯一非空键 | 可以是任意列或多列组合 |
| 是否占用更多空间 | 通常占用较大空间(含全部行数据) | 占用相对较少空间 |
| 适用场景 | 主键查找、排序、范围查询 | 辅助列查询、模糊查询、非主键搜索等 |
例如:
1 | CREATE TABLE users ( |
其中,id 是 聚集索引(InnoDB 会按它组织数据行);name 是 辅助索引,它的叶子节点只存储 id,查完整行时还得“回表”用 id 去找聚集索引
3. 查看、删除索引
如何查看表的索引
1 | SHOW INDEX FROM 表名; |
如何删除索引
1 | -- 普通索引 / 唯一索引 |
4. 创建索引
1 | INDEX A(B) |
✅ 1. 在建表时创建索引
1 | CREATE TABLE user ( |
✅ 2. 给已有表添加索引
1 | -- 🔹 添加普通索引: |
✅ 3. 使用 ALTER TABLE 添加索引
1 | ALTER TABLE user ADD INDEX idx_age (age); |
5. 测试索引
我们现在创建 $100$ 万条数据来测试索引在搜索时提高效率的作用:
1 | -- 创建100万条数据 |
然后,我们在表中搜索 name=user1 ,并使用 EXPLAIN 来查看查询时的具体信息:
1 | EXPLAIN SELECT * FROM `app_user` WHERE name='用户1' |
结果如图:

图片中字段 rows 这行显示为 $993939$,rows 表示 MySQL 预计需要读取多少行数据 才能找到满足条件的结果。它是预估值,不是精确值,由优化器根据统计信息计算得出。
显然,$993939$ 非常大,导致查询很慢,这个时候可以为 name 字段创建索引。
1 | CREATE INDEX `Name` ON `app_user`(name) |
随后再次执行查询,可以得到下图结果:

rows 会显著降低,查询效率大大提高。
为什么增加索引效率可以提高这么多呢?
索引能显著提升查询效率的根本原因是:它让数据库不必扫描整个表就能快速定位目标数据。
✅ 1. 通俗解释:就像查字典 vs. 全文翻书
想象一下你要在一本 1000 页的书里找 “苹果”:
❌ 没有目录(没有索引)你只能从第一页开始翻,看到哪里有“苹果”才停下——这就是全表扫描(type = ALL)。
✅ 有目录(索引)你直接翻到 “A” 页,立刻就找到“苹果”对应的页码,然后直达——这就是用到了索引(如 type = ref/const)。
📘 结论:索引 = 查数据的“目录”,避免全表一行行扫,速度自然飞快!
✅ 2. 技术解释:索引的数据结构
MySQL 默认使用 B+Tree(B 树的变种)结构作为索引,本质上属于空间换时间。
6. 索引原则
- 索引不是越多越好
- 不要对经常会变动数据加索引
- 小数据量的表不需要加索引
- 索引一般加在常用来查询的字段上
7. 索引的使用规则
组合索引遵循最左前缀原则
组合索引如 (a, b, c),查询 WHERE a AND b 可用索引,WHERE b AND c 则不能直接用到索引。
导致索引失效的情况
避免在索引列上使用函数或运算
例如 WHERE YEAR(create_time) = 2023 无法命中索引,应该改为 WHERE create_time BETWEEN ‘2023-01-01’ AND ‘2023-12-31’。
隐式类型转换(⚠️ 很容易忽略)
例如,对于字符串类型字段,使用索引时不加引号,
WHERE phone = 1234567890(phone 是字符串) 会把索引列转为int比较,导致失效。模糊匹配
如果仅仅是尾部模糊匹配,索引不会失效。如果是头部模糊匹配,索引将会失效。
OR 查询中部分条件未使用索引
例如,假设
name字段有索引,而age字段没有索引, 则WHERE name = 'Tom' OR age + 1 = 30整条查询索引都会失效。MySQL 优化器认为全表扫描更快
例如,对于小表或低选择性的字段(比如性别、状态),优化器会自动忽略索引
SQL 提示
SQL Hint 是你写在 SQL 语句中的特殊注释,用来告诉数据库优化器应该怎么执行 SQL,它们不会改变 SQL 的结果,但会影响执行策略。
例如,在索引使用中,假设同一个字段存在多个索引:
1
2
3
4
5
6
7CREATE TABLE users (
id INT PRIMARY KEY,
name VARCHAR(100),
age INT,
INDEX idx_name(name), -- 第一个索引
INDEX idx_name_age(name, age) -- 第二个索引,组合索引
);当执行以下查询时,MySQL 会从两个索引中选择它认为最优的一个:
1
SELECT * FROM users WHERE name = 'Tom';
但有时你想手动指定使用哪一个索引,比如强制用 idx_name,不用组合索引,这时就需要用**SQL Hint 指定索引。
1
2
3
4
5
6-- 建议mysql使用idx_name索引
SELECT * FROM users USE INDEX (idx_name) WHERE name = 'Tom';
-- 强制mysql优化器忽略你指定的索引
SELECT * FROM users IGNORE INDEX (idx_name_age) WHERE name = 'Tom';
-- 强制mysql使用idx_name索引
SELECT * FROM users FORCE INDEX (idx_name) WHERE name = 'Tom';Hint 类型 示例 含义 USE INDEX USE INDEX (idx_name) 推荐使用指定索引,但优化器可以不听 FORCE INDEX FORCE INDEX (idx_name) 强制使用指定索引 IGNORE INDEX IGNORE INDEX (idx_name_age) 忽略某个索引,不使用它 尽量使用覆盖索引
当一个查询所需的所有列都能从“索引本身”中获取,而不需要去访问原始数据行(回表)时,就叫**“覆盖索引”**。

对于这个问题,最优方案就是给 username、password 字段创建组合索引,这样查询时不会进行回表查询,效率更高。
前缀索引
前缀索引是指:只索引字符串字段的前 N 个字符,而不是整个字段内容,这是 MySQL 中针对 字符串字段(尤其是长字符串)的一种优化方式,常用于节省空间并提升查询效率。
1
2-- 语法
CREATE INDEX 索引名 ON 表名(列名(前缀长度));如何选择合适的前缀长度?
使用这个语句来分析字段前 N 位的区分度:
1
SELECT COUNT(DISTINCT LEFT(email, 20)) / COUNT(*) AS ratio FROM users;
ratio 越接近 1,说明前缀区分度越好,索引效果越好。
8. 索引的优缺点
| 优点 | 缺点 |
|---|---|
| 加快查询速度 | 占用额外的存储空间 |
| 提高排序和分组效率,不需要额外进行全表扫描或排序操作 | 增加写入成本(插入、更新、删除),每次数据的变更,索引也要同步更新 |
8. 权限管理与备份
8.1 用户管理
用户管理本质上都是在对 mysql.user 表进行增删查改。
✅ 一、查看当前有哪些用户
1 | SELECT User, Host FROM mysql.user; |
✅ 二、创建用户
1 | CREATE USER '用户名'@'主机' IDENTIFIED BY '密码'; |
示例:
1 | CREATE USER 'jack'@'localhost' IDENTIFIED BY '123456'; |
✅ 三、修改用户密码
1 | -- 使用 ALTER USER 修改密码(Recommend) |
✅ 四、重命名用户
1 | RENAME USER 'old_user'@'localhost' TO 'new_user'@'localhost'; |
✅ 五、删除用户
1 | DROP USER 'username'@'host'; |
✅ 六、授权(给用户赋权限)
1 | GRANT privileges ON database.table TO 'username'@'host'; |
常见权限:
ALL PRIVILEGES
SELECT, INSERT, UPDATE, DELETE
CREATE, DROP, ALTER
GRANT OPTION(允许该用户给别人授权)
✅ 七、查看用户权限
1 | SHOW GRANTS FOR 'username'@'host'; |
**✅ 八、撤销权限 **
1 | REVOKE privileges ON database.table FROM 'username'@'host'; |
8.2 MySQL 备份
MySQL 数据库备份的方式:
1 | mysqldump -h 主机 -u 用户名 -p 密码 数据库 表名 > 物理磁盘位置 |
MySQL 导入数据的方式:
1 | # 在终端中导入 |
如果已经登录了 sql,则可以按照以下方式导入:
1 | source /Users/yourname/Desktop/mydb_backup.sql; |
9. 规范设计数据库
9.1 三大范式
第一范式(1NF)
原子性:保证每一列不可再分
第二范式(2NF)
前提: 满足第一范式
每张表只描述一件事情
第三范式(3NF)
前提:满足第一范式和第二范式
第一范式(1NF)——字段不可再分(原子性)
✅ 定义:
关系数据库中的每一个字段(列)必须是不可再分的最小单位,也就是说,不能包含列表、数组、表格、结构体之类的数据。
❌ 不符合示例:
| 学号 | 姓名 | 电话号码 |
|---|---|---|
| 1001 | 张三 | 13800001111,13900002222 |
✅ 正确示例:
| 学号 | 姓名 | 电话号码 |
|---|---|---|
| 1001 | 张三 | 13800001111 |
| 1001 | 张三 | 13900002222 |
第二范式(2NF)——消除部分依赖
✅ 定义:
在满足 1NF 的前提下,表中所有非主属性必须完全依赖于整个主键,不能只依赖主键的一部分
只有在主键是“复合主键”时,第二范式才有意义(单一主键不会存在部分依赖)。
❌ 不符合示例:
学生选课表(学号, 课程编号)为主键:
| 学号 | 课程编号 | 姓名 |
|---|---|---|
| 1001 | C01 | 张三 |
→ 姓名只依赖于“学号”,不是依赖整个主键(学号 + 课程编号),违反 2NF。
✅ 正确做法:
学生表:
| 学号 | 姓名 |
|---|---|
| 1001 | 张三 |
选课表:
| 学号 | 课程编号 |
|---|---|
| 1001 | C01 |
第三范式(3NF)——消除传递依赖
✅ 定义:
在满足 2NF 的前提下,非主属性不能依赖于其他非主属性,即不能通过其他字段“间接”依赖主键。
❌ 不符合示例:
| 学号 | 姓名 | 院系编号 | 院系名称 |
|---|---|---|---|
| 1001 | 张三 | D01 | 信息工程 |
✅ 正确做法:
学生表:
| 学号 | 姓名 | 院系编号 |
|---|---|---|
| 1001 | 张三 | D01 |
院系表:
| 院系编号 | 院系名称 |
|---|---|
| D01 | 信息工程 |


